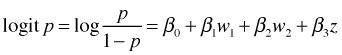
I reload the wells data set, collapse the landscape categories, and fit the final models from last time.
The logistic regression model with dummy variables for sewer (z) and land use (w1 and w2) is the following.
The usual convention in generalized linear models is to use the Greek letter η to denote the linear predictor in a model.
![]()
Letting η denote the linear predictor in the model, I solve the logistic regression equation for p, the probability of contamination.
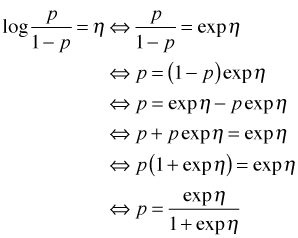
The function of η on the right hand side of the last expression is the inverse logit. It's also called the logistic function. Suppose we want a point estimate for the probability of contamination for a well in a mixed land use area in which sewers are present. This corresponds to w1 = 1, w2 = 0, and z = 1 in our model. Thus η is the following.
![]()
The inverse logit of this expression is the desired probability.
If all we need are the predicted probabilities associated with individual observations we don't need to do this calculation ourselves. The predict function with type='response' when applied to a logistic regression model returns probabilities. We can even include the se.fit = T option to obtain standard errors of the probabilities.
$se.fit
1 2 3 4 5 6
0.029363994 0.006720644 0.029363994 0.006720644 0.033727179 0.014394246
7 8 9 10 11 12
0.033727179 0.014394246 0.039023551 0.038406497 0.033727179 0.014394246
13 14 15 16 17 18
0.033727179 0.014394246 0.033727179 0.014394246 0.039023551 0.038406497
19 20
0.039023551 0.038406497
If we could assume that the probabilities are normally distributed then we could use the output from predict to obtain 95% normal-based confidence intervals for the probabilities with the usual formula:
![]()
The general guideline for when this formula is appropriate was mentioned previously. Typically we need both ![]() and
and ![]() . Checking this for these data we find
. Checking this for these data we find
So only 8 of the 20 wells satisfy this criterion. Thus the normal approximation is suspect here. We can see that there is a problem if we use this formula to calculate a confidence interval for the first observation.
The interval has a negative left hand endpoint so negative probabilities are included in the confidence interval. This is clearly silly.
A better approach is to parallel what we did to obtain confidence intervals for odds ratios. Because maximum likelihood estimates have an asymptotic normal distribution, so do linear combinations of maximum likelihood estimates. So we start by obtaining a 95% confidence interval for the linear combination η (on the logit scale). We then apply the inverse logit function separately to the endpoints of the interval to obtain a confidence interval for the probability. To obtain the confidence intervals on the logit scale we have two choices: we can construct Wald-type confidence intervals or profile likelihood confidence intervals.
We start by creating a data frame containing all possible combinations of sewer and land.use4.
Next we use this in the newdata argument of predict to obtain the predicted logits and their standard errors and add them to the data frame.
$se.fit
1 2 3 4 5 6
0.2992586 0.2605273 0.7304131 0.1574256 0.1931381 0.7310097
$residual.scale
[1] 1
Next we calculate normal-based 95% confidence intervals for the predicted logits.
Finally we apply the inverse logit function to the logit column and the columns containing the endpoints of the confidence intervals.
Assembling everything in a data frame yields the following.
The function confint calculates profile likelihood confidence intervals for the parameters estimated by a glm model. To make use of it here we need to reparameterize the glm model so that the returned parameter estimates correspond to individual categories of sewer and land use, rather than effects. We can accomplish this in two stages. First we obtain the logits for the three land.use4 categories when sewer = 'no' by refitting the model without an intercept.
To get the predicted land use logits when sewer = 'yes' we redefine the levels of the sewer factor so that sewer = 'yes' is the reference group and then refit the model without an intercept.
Finally we assemble the logits and confidence intervals in a matrix and add the land use and sewer identifiers.
We start by creating a unique identifier for each combined sewer and land use category. The numeric version of this variable defines the tick marks on the y-axis of the plot.
The rest of the code for this is very much like what we used in lecture 4 for a similar graph.
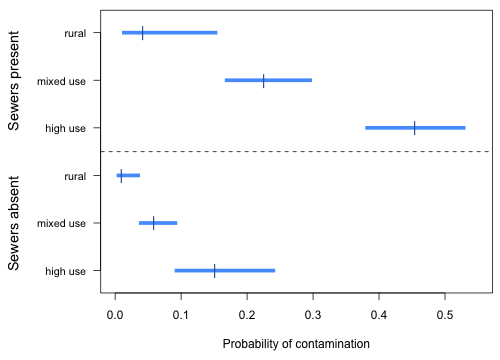 |
| Fig. 1 Estimated sewer and land use category probabilities along with 95% confidence intervals |
This is analogous to the interaction plots we did for a two-factor ANOVA. Notice that the probability profiles are not parallel on a probability scale even though there is no interaction between sewer and land use in the model. This happens because even though on a logit scale we have an additive model in sewer and land use type, the inverse logit is a nonlinear transformation from the logit scale to the probability scale.
If there are continuous predictors in a model then we can't produce diagrams of probabilities such as Fig. 1 unless we choose specific values for the continuous predictors (the mean is often a good choice). If after stratifying the continuous predictors by the categorical predictors there is no overlap in the range of the continuous predictors then this approach is not appropriate. It doesn't make sense to obtain a predicted probability for a value of a predictor if that value doesn't occur within the range of the data for a particular category.
Consider the model we fit that contained land.use4, sewer, and nitrate. When we stratify the continuous variable nitrate by the categorical variables land.use4 and sewer, we see that the nitrate values in the land.use4 = 'rural' and sewer = 'yes' category only overlap two of the other five categories.
When there is a single continuous predictor in a logistic regression model there is another way of summarizing the results—plot the fitted model against the continuous variable on a probability scale. Combinations of levels of categorical variables in the model correspond to separate logistic curves. When there are two or more continuous variables in the model then plotting the model on a probability scale is not possible unless we are willing to plot the probability as a function of one of the continuous variables while holding the other continuous variables fixed at some values. Three-dimensional graphs and contour plots are often difficult to interpret in logistic regression.
I plot the model out2i that contains the continuous predictor nitrate and the categorical predictors land.use4 with three levels and sewer with two levels. The categorical variables combine to yield six different logit curves as functions of nitrate. I construct a function for the fitted logistic regression model that returns the value of the logit as a function of nitrate and the three dummy variables in the model.
Using the inverse logit function we can construct a function that returns probabilities as a function of nitrate and the three dummy variables in the model.
Finally I determine the overall range of the continuous variable in the data set as well as separately by category and use this in determining the domain for each curve.
I use the individual ranges to restrict the curve function so that the curve is only drawn over an interval of nitrate values that were actually observed for that category.
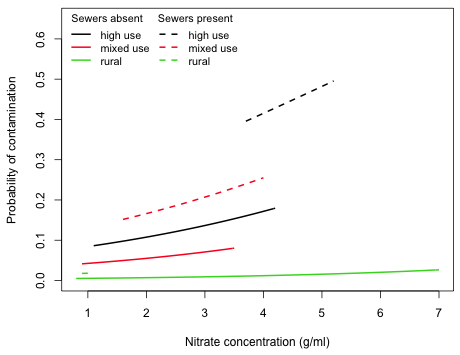 |
| Fig. 2 Plot of the individual predicted logistic functions (inverse logits) as a function of nitrate concentration separately by land use category and sewer |
We would need to extend the curves beyond the range of the data to see the sigmoid shape that characterizes the logistic function.
A useful way to graphically display the summary table of the model is to plot odds ratios (or log odds ratios) corresponding to the various terms in the model along with their confidence intervals. This can be done with both categorical and continuous variables although with continuous variables we will need to choose an appropriate increment in order to make the display comparable with the rest.
To optimize the use of space in the graph, it is useful when possible to arrange the coding of factors so that all of the log odds ratios have the same sign. For the current model we can accomplish this by reordering the land.use4 factor so that the "rural" category is the reference group.
Next we obtain the confidence intervals on the logit scale and assemble things in a data frame.
The variable var denotes the locations on the y-axis for the individual confidence intervals. In constructing labels for the log odds ratios I use the escape character, \n, inside the text string to force the labels to break over two lines.
The rest of the code resembles work we've done previously. A prepanel function is used to ensure that the x-limits of the graph are determined from the confidence intervals, not from the point estimates of the log odds ratios.
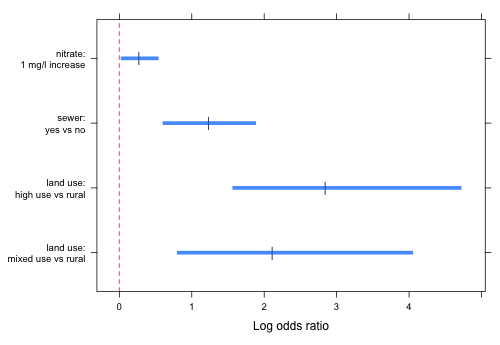 |
| Fig. 3 Log odds ratios and 95% confidence intervals corresponding to all of the individual estimated effects. |
It's generally a better choice to display odds ratios than log odds ratios because they're more interpretable. For this problem I chose log odds ratios because the confidence intervals for the odds ratios are so wide for the two land use effects that they would swamp the rest of the graph making it difficult to even see the remaining estimates.
Consider the following data set that contains the results of a binomial experiment with a two-level treatment that was administered in blocks.
Block_Number Treatment killedThe last column reports the number of crabs killed in a total of 6 trials for two different treatments numbered 1 and 2. The treatments are arranged in 16 blocks, so we can presume that the observations coming from the same block are more similar to each other than they are to observations from different blocks. We can copy the displayed data to the clipboard and read the data directly into R. The syntax for doing this is different for Windows and Mac OS X.
One way to analyze a randomized block design is to treat the blocks as fixed effects and include them in a logistic regression model as a factor.
Deviance Residuals:
Min 1Q Median 3Q Max
-3.09746 -0.93741 -0.00829 1.33889 3.09746
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.421e+00 7.907e-01 1.797 0.07241 .
factor(Treatment)2 4.050e-01 3.420e-01 1.184 0.23629
factor(Block_Number)2 7.918e-01 1.303e+00 0.608 0.54336
factor(Block_Number)3 -1.623e+00 9.699e-01 -1.674 0.09423 .
factor(Block_Number)4 -1.708e-15 1.099e+00 0.000 1.00000
factor(Block_Number)5 -1.623e+00 9.699e-01 -1.674 0.09423 .
factor(Block_Number)6 -1.623e+00 9.699e-01 -1.674 0.09423 .
factor(Block_Number)7 -1.283e+00 9.747e-01 -1.317 0.18799
factor(Block_Number)8 -5.142e-01 1.025e+00 -0.502 0.61598
factor(Block_Number)9 -4.038e+00 1.304e+00 -3.097 0.00196 **
factor(Block_Number)10 1.275e-10 1.099e+00 0.000 1.00000
factor(Block_Number)11 -4.038e+00 1.304e+00 -3.097 0.00196 **
factor(Block_Number)12 -1.623e+00 9.699e-01 -1.674 0.09423 .
factor(Block_Number)13 -2.323e+00 9.915e-01 -2.343 0.01912 *
factor(Block_Number)14 -2.732e+00 1.026e+00 -2.663 0.00776 **
factor(Block_Number)15 -5.142e-01 1.025e+00 -0.502 0.61600
factor(Block_Number)16 -9.231e-01 9.909e-01 -0.932 0.35157
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 155.692 on 31 degrees of freedom
Residual deviance: 97.612 on 15 degrees of freedom
AIC: 164.58
Number of Fisher Scoring iterations: 4
While the fixed effects model has successfully tested for a treatment effect (and found it to be not significant), we're left with a mess of uninteresting block effects to sort through. Furthermore if we want to estimate the probability that a particular treatment kills a crab, we can only do so for individual blocks. For instance an inverse logit applied to the intercept in the current model yields the probability that treatment 1 kills crabs, but only in block 1.
The solution to this as we saw in lecture 6 is to treat blocks as a random effect in which we view the individual blocks as deviations from an average block, which hopefully represents the average in the population from which the blocks were drawn. The lmer function of the lme4 package will fit a random intercepts model with a binomial response.
Fixed effects:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.08411 0.34819 0.242 0.809
factor(Treatment)2 0.36983 0.31710 1.166 0.244
Correlation of Fixed Effects:
(Intr)
fctr(Trtm)2 -0.446
As before we fail to find a difference in the two treatments. Unlike the fixed effects model where the intercept represented the log odds of death for treatment 1 in block 1 now it represents the log odds of death for treatment 1 for an average block. Note: to say that a log odds of death is not significantly different from zero is equivalent to saying that the probability of death is not different from 0.5.
A compact collection of all the R code displayed in this document appears here.
| Jack Weiss Phone: (919) 962-5930 E-Mail: jack_weiss@unc.edu Address: Curriculum for the Environment and Ecology, Box 3275, University of North Carolina, Chapel Hill, 27599 Copyright © 2012 Last Revised--December 5, 2012 URL: https://sakai.unc.edu/access/content/group/3d1eb92e-7848-4f55-90c3-7c72a54e7e43/public/docs/lectures/lecture28.htm |