Lecture 8—Wednesday, September 19, 2012
Topics
R functions and commands demonstrated
- panel.superpose (from lattice) is the panel function used with groups to indicate that individual groups are to be distinguished within panels. It can be used with a user-specified panel.groups function for customized displays.
- useOuterStrips (from latticeExtra) can be used to place panels on the left edge and the top edge of panel graphs.
R function options
- group.number is a key word available in lattice for identifying the observations that are being used in the current group.
- groups= (argument to lattice functions) defines the grouping variable in lattice graphs. Grouping variables affect the display in a single panel while conditioning variables affect the display in different panels.
- prepanel= (argument to xyplot) identifies a user-defined prepanel function that determines the x- and/or y-limits for individual panels.
Additional R packages used
Obtaining the variance-covariance matrix for means
I refit the model we ended with last time: a 4-factor model consisting of a two-factor interaction, two additional main effects, and crossed random effects that describe variability across blocks and species.
nitro <- read.csv(ecol 563/nitro.csv')
library(lme4)
mod3.lmer <- lmer(pN^2 ~ factor(lh)*factor(n) + factor(func) + factor(p) + (1|block) + (1|phy), data=nitro[nitro$tag!=444,])
The goal today is to produce a single graph that summarizes the treatment structure of this experiment. The centerpiece for the graphical display will be a depiction of the two-factor interaction between lh and n separately for different levels of func and p. The main effects of func and p will serve to shift this interaction vertically along the y-axis yielding four identical two-factor interaction diagrams. Because the main effects of func and p are statistically significant the individual means on different two-factor interactions diagrams will be significantly different from each other. Thus in constructing the graph we can focus on pairwise differences between the means on a single interaction diagram. To summarize the pairwise differences we'll superimpose difference-adjusted confidence intervals for individual means on top of the interaction diagram. To do this we'll need to obtain the variance-covariance matrix of the means.
A shortcut for obtaining the variance-covariance matrix of the means
The vcov function when applied to a model returns the variance-covariance matrix of the parameter estimates.
vcov(mod3.lmer)
6 x 6 Matrix of class "dpoMatrix"
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1.9346509 -0.453938419 -0.4390415812 -0.1886031778 -0.23563174 0.425476994
[2,] -0.4539384 0.886624290 0.4517868719 -0.0076226170 0.05107698 -0.825869604
[3,] -0.4390416 0.451786872 0.7211081354 -0.0006052021 0.05602064 -0.711296357
[4,] -0.1886032 -0.007622617 -0.0006052021 0.3760469051 0.00216406 0.005892231
[5,] -0.2356317 0.051076985 0.0560206445 0.0021640597 0.39716929 -0.030612977
[6,] 0.4254770 -0.825869604 -0.7112963573 0.0058922311 -0.03061298 1.613440076
The parameter estimates here are effect estimates, not individual treatment means. For certain models it is possible to force R to reparameterize the model so that it returns cell means rather than effect estimates. It is not possible to do this with the model currently under consideration, but if the model were slightly simpler we could. Suppose the final model consisted only of the two factor interaction between lh and n.
mod4.lmer <- lmer(pN^2 ~ factor(lh)*factor(n) + (1|block) + (1|phy), data=nitro[nitro$tag!=444,])
If we replace the term factor(lh)*factor(n) with the expression factor(lh):factor(n)-1, the parameters that R returns are the treatment means. This expression appears to fit a model with an interaction but without main effects and an intercept. Rather than fit such a silly model R instead estimates each category of the interaction term separately replacing the intercept and main effects with the separate category estimates. We still get four parameters but now instead of obtaining a mean and three effect estimates we obtain four treatment means.
mod4a.lmer <- lmer(pN^2 ~ factor(lh):factor(n)-1 + (1|block) + (1|phy), data=nitro[nitro$tag!=444,])
fixef(mod4a.lmer)
factor(lh)EA:factor(n)0 factor(lh)NP:factor(n)0 factor(lh)EA:factor(n)1
15.06911 12.82419 21.12087
factor(lh)NP:factor(n)1
15.36462
The vcov function applied to this model yields the variance-covariance matrix of the means.
vcov(mod4a.lmer)
4 x 4 Matrix of class "dpoMatrix"
[,1] [,2] [,3] [,4]
[1,] 2.007396 1.522721 1.546673 1.526800
[2,] 1.522721 2.035577 1.565918 1.613134
[3,] 1.546673 1.565918 1.893979 1.577494
[4,] 1.526800 1.613134 1.577494 2.221533
If our model consisted of only a single factor, say lh, then removing the intercept from this model would cause R to estimate the treatment means at both levels of lh.
# effect estimates
mod5.lmer <- lmer(pN^2 ~ factor(lh) + (1|block) + (1|phy), data=nitro[nitro$tag!=444,])
fixef(mod5.lmer)
(Intercept) factor(lh)NP
18.509550 -4.965262
# remove intercept to get category mean estimates
mod5a.lmer <- lmer(pN^2 ~ factor(lh)-1 + (1|block) + (1|phy), data=nitro[nitro$tag!=444,])
fixef(mod5a.lmer)
factor(lh)EA factor(lh)NP
18.50955 13.54429
The vcov function applied to this model yields the variance-covariance matrix of the means.
vcov(mod5a.lmer)
2 x 2 Matrix of class "dpoMatrix"
[,1] [,2]
[1,] 2.100850 1.833949
[2,] 1.833949 2.258722
Using the estimates of the effects to obtain the variance-covariance matrix of the means
The shortcut method won't work for the current model because it is too complicated. We'll need to construct a contrast matrix C such that when multiplied by the vector of regression parameter estimates it returns the treatment means for the treatments of interest. We've done this previously and the same approach will work here. The only difference is that we're working with a model estimated by lmer rather than by lm. We need to write a function that generates the values of the dummy variables in the same order as the coefficients estimated by lmer. To see this order I examine the names of the coefficient estimates and construct a function whose arguments are the values of the four factors.
fixef(mod3.lmer)
(Intercept) factor(lh)NP factor(n)1
12.980958 -2.046807 6.309203
factor(func)mock factor(p)1 factor(lh)NP:factor(n)1
1.974241 1.875379 -3.613860
cmat2 <- function(lh,n,func,p) c(1, lh=='NP', n==1, func=='mock', p==1, (lh=='NP')*(n==1))
I construct a matrix that contains all the possible combinations of the values of lh and n.
g <- expand.grid(lh=levels(nitro$lh), n=0:1)
g
lh n
1 EA 0
2 NP 0
3 EA 1
4 NP 1
I specify the values func = 'inoc' and p = 0 and evaluate the function separately on the rows of this matrix by using the apply function. Because apply extracts each row of the matrix as a vector (each a vector of length 2) I reformulate the function cmat2 as a generic function in which the first two arguments are elements 1 and 2 of a vector.
apply(g,1, function(x) cmat2(x[1], x[2], 'inoc', 0))
[,1] [,2] [,3] [,4]
1 1 1 1
lh 0 1 0 1
n 0 0 1 1
0 0 0 0
0 0 0 0
lh 0 0 0 1
The contrast matrix we need is the transpose of this matrix.
# transpose result
t(apply(g,1, function(x) cmat2(x[1],x[2],'inoc',0)))
lh n lh
[1,] 1 0 0 0 0 0
[2,] 1 1 0 0 0 0
[3,] 1 0 1 0 0 0
[4,] 1 1 1 0 0 1
Finally I set this up as a function with arguments func and p.
cmat3 <- function(func,p) t(apply(g, 1, function(x) cmat2(x[1], x[2], func, p)))
cmat3('inoc',0)
lh n lh
[1,] 1 0 0 0 0 0
[2,] 1 1 0 0 0 0
[3,] 1 0 1 0 0 0
[4,] 1 1 1 0 0 1
I use the function to calculate the treatment means and the variance-covariance matrix of the means for func = 'inoc' and p = 0.
#obtain estimates of the means
ests <- cmat3('inoc',0) %*% fixef(mod3.lmer)
#obtain the variance-covariance matrix of the means
vmat <- cmat3('inoc',0) %*% vcov(mod3.lmer) %*% t(cmat3('inoc',0))
ests
[,1]
[1,] 12.98096
[2,] 10.93415
[3,] 19.29016
[4,] 13.62949
vmat
4 x 4 Matrix of class "dgeMatrix"
[,1] [,2] [,3] [,4]
[1,] 1.934651 1.480712 1.495609 1.467148
[2,] 1.480712 1.913398 1.493458 1.525751
[3,] 1.495609 1.493458 1.777676 1.489705
[4,] 1.467148 1.525751 1.489705 2.050059
Calculating difference-adjusted confidence intervals for the treatment means
To obtain the confidence level for the precision-based confidence intervals we need to modify the function we used previously. That function used a t-distribution with the residual degrees of freedom from the model as the multiplier. As was discussed in lecture 6 the determination of degrees of freedom in mixed effects models is problematic. Instead we'll assume that a normal distribution is an adequate substitute. I replace the occurrences of qt and pt with qnorm and pnorm respectively and remove the degrees of freedom argument. I also eliminate the second argument of the ci.func function. This was the fitted regression model, which was used only to extract the degrees of freedom for the t-distribution.
ci.func2 <- function(rowvals, glm.vmat) {
nor.func1a <- function(alpha, sig) 1-pnorm(-qnorm(1-alpha/2) * sum(sqrt(diag(sig))) / sqrt(c(1,-1) %*% sig %*%c (1,-1))) - pnorm(qnorm(1-alpha/2) * sum(sqrt(diag(sig))) / sqrt(c(1,-1) %*% sig %*% c(1,-1)), lower.tail=F)
nor.func2 <- function(a,sigma) nor.func1a(a,sigma)-.95
n <- length(rowvals)
xvec1b <- numeric(n*(n-1)/2)
vmat <- glm.vmat[rowvals,rowvals]
ind <- 1
for(i in 1:(n-1)) {
for(j in (i+1):n){
sig <- vmat[c(i,j), c(i,j)]
#solve for alpha
xvec1b[ind] <- uniroot(function(x) nor.func2(x, sig), c(.001,.999))$root
ind <- ind+1
}}
1-xvec1b
}
We have four means so the first argument to this function is 1:4. If I use the function on the variance-covariance matrix vmat we calculated above R issues an error message.
ci.func2(1:4, vmat)
Error in pnorm(q, mean, sd, lower.tail, log.p) :
Non-numeric argument to mathematical function
The problem appears to be that the pnorm and qnorm functions don't recognize the class of vmat, "dgeMatrix", that it inherited from the lme4 package. If I use the as.matrix function to change the class of vmat to "matrix" the function works.
class(vmat)
[1] "dgeMatrix"
attr(,"package")
[1] "Matrix"
# we need to change the class to type matrix
class(as.matrix(vmat))
[1] "matrix"
ci.func2(1:4, as.matrix(vmat))
[1] 0.4941076 0.4587715 0.5233151 0.4550982 0.4938757 0.4861521
When I try the function on a different variance-covariance matrix obtained with different choices for func and p, I get slightly different results.
vmat1 <- cmat3('inoc',1) %*% vcov(mod3.lmer) %*% t(cmat3('inoc',1))
ci.func2(1:4, as.matrix(vmat1))
[1] 0.4966934 0.4606688 0.5232543 0.4515150 0.4882857 0.4799260
vmat2 <- cmat3('mock',0) %*% vcov(mod3.lmer) %*% t(cmat3('mock',0))
ci.func2(1:4, as.matrix(vmat2))
[1] 0.4950842 0.4589653 0.5236987 0.4561144 0.4950836 0.4865980
vmat3 <- cmat3('mock',1) %*% vcov(mod3.lmer) %*% t(cmat3('mock',1))
ci.func2(1:4,as.matrix(vmat3))
[1] 0.4971857 0.4603868 0.5231534 0.4520464 0.4890052 0.4798944
These differences are probably not large enough to matter but I elect to obtain separate confidence levels for each of the combinations of func and p anyway. To this end I write a function that obtains the difference-adjusted confidence levels, calculates the 95% and difference-adjusted confidence intervals, and assembles them along with the means and the appropriate labels in a data frame. In the function I use the lowest difference-adjusted confidence level that was obtained for all the comparisons. It turns out that if we repeat this using the largest calculated confidence level the conclusions we would draw from the graph don't change.
make.data <- function(func,p,model) {
#variance-covariance matrix of the means
vmat <- cmat3(func,p) %*% vcov(model) %*% t(cmat3(func,p))
# difference-adjusted confidence levels
vals1 <- ci.func2(1:4, as.matrix(vmat))
# levels of lh and n, means, and standard errors
part1 <- data.frame(lh=c('EA','NP','EA','NP'), n=c(0,0,1,1),
est=as.vector(cmat3(func,p)%*%fixef(model)), se=sqrt(diag(vmat)))
# 95% intervals
part1$low95 <- part1$est + qnorm(.025)*part1$se
part1$up95 <- part1$est + qnorm(.975)*part1$se
# difference-adjusted intervals
part1$low85 <- part1$est + qnorm((1-min(vals1))/2)*part1$se
part1$up85 <- part1$est + qnorm(1-(1-min(vals1))/2)*part1$se
# add value of func and p
part1$func <- func
part1$p <- p
# return value of function
part1
}
Finally I use the function separately for the four different combinations of func and p and assemble the results in a single data frame.
part0a <- make.data('inoc', 0, mod3.lmer)
part0b <- make.data('inoc', 1, mod3.lmer)
part0c <- make.data('mock', 0, mod3.lmer)
part0d <- make.data('mock', 1, mod3.lmer)
# assemble results in single matrix
fac.vals <- rbind(part0a, part0b, part0c, part0d)
fac.vals
lh n est se low95 up95 low85 up85 func p
1 EA 0 12.98096 1.390917 10.254810 15.70711 12.13887 13.82304 inoc 0
2 NP 0 10.93415 1.383256 8.223018 13.64528 10.09670 11.77160 inoc 0
3 EA 1 19.29016 1.333295 16.676950 21.90337 18.48296 20.09736 inoc 0
4 NP 1 13.62949 1.431803 10.823212 16.43578 12.76266 14.49633 inoc 0
5 EA 0 14.85634 1.364022 12.182903 17.52977 14.03788 15.67479 inoc 1
6 NP 0 12.80953 1.393362 10.078590 15.54047 11.97347 13.64559 inoc 1
7 EA 1 21.16554 1.347451 18.524585 23.80649 20.35703 21.97405 inoc 1
8 NP 1 15.50487 1.459087 12.645115 18.36463 14.62937 16.38037 inoc 1
9 EA 0 14.95520 1.390500 12.229868 17.68053 14.11124 15.79916 mock 0
10 NP 0 12.90839 1.377314 10.208906 15.60788 12.07243 13.74435 mock 0
11 EA 1 21.26440 1.332406 18.652934 23.87587 20.45570 22.07310 mock 0
12 NP 1 15.60373 1.429765 12.801446 18.40602 14.73594 16.47153 mock 0
13 EA 0 16.83058 1.365183 14.154868 19.50629 16.01034 17.65082 mock 1
14 NP 0 14.78377 1.389022 12.061338 17.50620 13.94921 15.61834 mock 1
15 EA 1 23.13978 1.348177 20.497403 25.78216 22.32976 23.94981 mock 1
16 NP 1 17.47911 1.458572 14.620366 20.33786 16.60276 18.35547 mock 1
Creating an interaction plot using the lattice package
Previously we created an interaction plot using base graphics. Here I illustrate doing the same using the lattice package. While we could do something similar to what we did before where we subsetted the data and first drew one profile then the other, it is far more efficient to use the groups argument in lattice. We've use it previously to obtain different colors and symbol types when plotting different groups. We can do more elaborate things separately by group if we create our own group panel function.
Group panel function
When the groups argument is included lattice calls a specific panel function called panel.superpose. The panel.superpose function in turn calls something called a panel.groups function that by default is panel.xyplot in which the points are colored separately by group. To draw the error bars we will need to create our own customized panel.groups function. Here's the function I created followed by an explanation of the various parts of the code.
# group panel function
my.panel <- function(x, y, subscripts, col, pch, group.number, ...) {
#subset variables for the current panel
low95 <- fac.vals$low95[subscripts]
up95 <- fac.vals$up95[subscripts]
low85 <- fac.vals$low85[subscripts]
up85 <- fac.vals$up85[subscripts]
myjitter <- c(-.05,.05)
col2 <- c('tomato','grey60')
#95% confidence interval
panel.arrows(x+myjitter[group.number], low95, x+myjitter[group.number], up95, angle=90,
code=3, length=.05, col=col)
#difference-adjusted confidence interval
panel.segments(x+myjitter[group.number], low85, x+myjitter[group.number], up85,
col=col2[group.number], lineend=1, lwd=5)
# connect means with line segments
panel.lines(x+myjitter[group.number], y, col=col)
# add point estimates for the means
panel.xyplot(x+myjitter[group.number], y, col='white', pch=16)
panel.xyplot(x+myjitter[group.number], y, col=col, pch=pch, ...)
# grid lines
panel.abline(h=seq(10,26,2), col='lightgrey', lty=3)
}
I pass to the group panel function the colors and plot characters I want it to use for the groups (the col and pch arguments in the function definition). The subscripts argument was explained previously and will be used to get the correct observations for use in the current panel for variables that were not included in the original function call. Notice the ... notation that appears in a couple of places. It's used so that any additional arguments that lattice would normally need in displaying groups get passed to the appropriate functions. One new argument is group.number. It records the number of the group currently being drawn. It will have the value 1 or 2 here because there are only two groups.
The first four lines of the function use the subscripts variable to select the confidence bounds that are appropriate for the panel currently being drawn. When the panel function is called upon to draw a panel the variable subscripts identifies the observations whose values of func and p (the variables that defines the panels) are being used for the current panel. So, in the above code the expressions fac.vals$low95[subscripts] and fac.vals$up95[subscripts] extract a vector of lower 95% endpoints and a vector of upper 95% endpoints corresponding to the level of the conditioning variable that is currently being plotted. This is also the role the notation x and y have in the function. By default each time a panel is drawn the correct set of lh and est values (the x and y variables) are selected. Because low95, up95 , low85, and up85 are not part of the original function call we have to extract the correct set of observations for the panel ourselves.
The myjitter variable denotes the amount I want to shift the error bars for the two profiles. The col2 variable contains the colors for the difference-adjusted confidence intervals. The panel.arrows and panel.segments functions are just the lattice version of the arrows and segments functions of base graphics. Notice how I use the group.number variable to select the correct value for myjiitter and the correct color for the difference-adjusted error bars for the current group being plotted.
Prepanel function
Ordinarily lattice uses the variables in the main function call to determine the appropriate x-limits and y-limits of the graph. We've previously overridden this choice by specifying the xlim and ylim arguments, which forces the limits in all the panels to be the same. If we would like the limits to potentially vary between panels we can supply a prepanel function in which we pass to it those variables that are needed to calculate the correct limits. Below is a prepanel function that uses the values of the variables y, ly, and uy to reset the limits on the y-axis. Its return value is the new setting of ylim for the panel currently being drawn.
# prepanel function to set limits for panels
prepanel.ci2 <- function(x, y, ly, uy, subscripts, ...){
list(ylim=range(y, uy[subscripts], ly[subscripts], finite=T))}
In the function call I will specify uy and ly to be the variables containing the upper 95% and lower 95% confidence bounds.
Drawing the graph
The call to lattice to produce the graph is shown below.
library(lattice)
# two-factor interaction plot using lattice and group panel function
xyplot(est~lh|func+factor(p, level=0:1, labels=paste('P = ', 0:1, sep='')),
xlab ='lh', ylab='Estimated mean', groups=factor(n), data=fac.vals, col=c(2,1),
pch=c(1,16), prepanel=prepanel.ci2, ly=fac.vals$low95, uy=fac.vals$up95,
layout=c(2,2), panel.groups=my.panel, panel="panel.superpose")
- The summation expression after the vertical bar defines the panels. In this case func+factor(p, level=0:1, labels=paste('P = ', 0:1, sep='')) will cause the panels to be defined by all combinations of the levels of func and p.
- In the conditioning expression I explicitly declare p to be a factor in order to create more informative labels for the factor levels: "P = 0" and "P = 1".
- groups = factor(n) declares the levels of n as defining the groups.
- col=c(2,1) and pch=c(1,16) are the values that will be passed to the group panel function for use when drawing the groups.
- prepanel=prepanel.ci2 identifies the function prepanel.ci2 as the panel function that should be used.
- ly=fac.vals$low95 and uy=fac.vals$up95 are the two values required by the prepanel function we wrote.
- layout=c(2,2) causes the panels to be arranged in two columns and two rows.
- panel.groups=my.panel identifies the group panel function that we created.
- panel="panel.superpose" calls the default panel function that will then call the panel.groups function. If there were any panel features that we wanted to add that did not vary by groups we could have written our own panel function and specified it here.
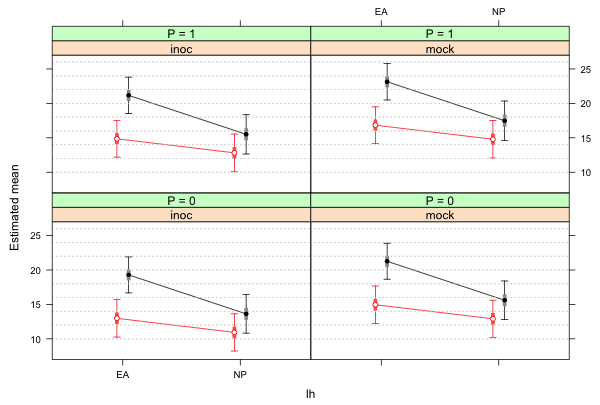 |
| Fig. 1 Two-factor interaction panel graph produced by lattice |
Adding a key
The use of the key argument was explained in lecture 7. I redo the previous graph but this time add a legend.
# add a key to the graph
xyplot(est~lh|func+factor(p, level=0:1, labels=paste('P = ', 0:1, sep='')),
xlab ='lh', ylab='Estimated mean', groups=factor(n), data=fac.vals, col=c(2,1),
pch=c(1,16), prepanel=prepanel.ci2, ly=fac.vals$low95, uy=fac.vals$up95,
layout=c(2,2), panel.groups=my.panel, panel="panel.superpose",
key=list(x=.87, y=.82, corner=c(0,0), points=list(pch=c(16,1), col=1:2, cex=.9),
text=list(c('n = 1','n = 0'), cex=.8)))
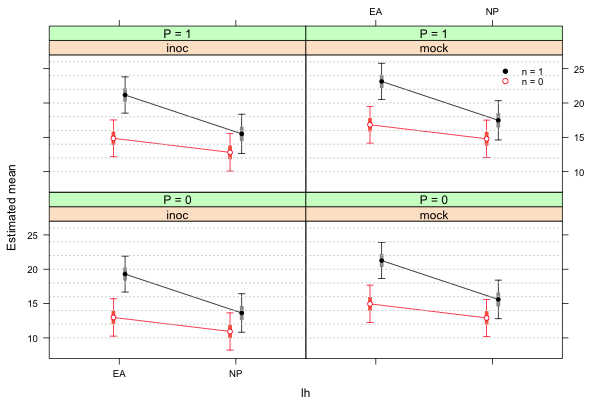 |
| Fig. 2 Two-factor interaction panel graph with a legend |
Improving the display with the latticeExtra package
The latticeExtra package adds some additional features to the lattice package. One of those features is to allow panel strips on both the sides and tops of the panels. This is possible when the conditioning variable is written as a sum of two factors as it is here. Lattice graphs can be saved as objects that can then be manipulated with functions from latticeExtra. The useOuterStrips function from the latticeExtra package will put panel strips on the left and on the top of the graph.
mygraph <-
xyplot(est~lh|func+factor(p, level=0:1, labels=paste('P = ', 0:1, sep='')),
xlab ='lh', ylab='Estimated mean', groups=factor(n), data=fac.vals, col=c(2,1),
pch=c(1,16), prepanel=prepanel.ci2, ly=fac.vals$low95, uy=fac.vals$up95,
layout=c(2,2), panel.groups=my.panel, panel="panel.superpose",
key=list(x=.87,y=.88, corner=c(0,0), points=list(pch=c(16,1), col=1:2, cex=.9),
text=list(c('n = 1','n = 0'), cex=.8)))
# load the latticeExtra package and redo graph
library(latticeExtra)
# put strips on left and on top
useOuterStrips(mygraph)
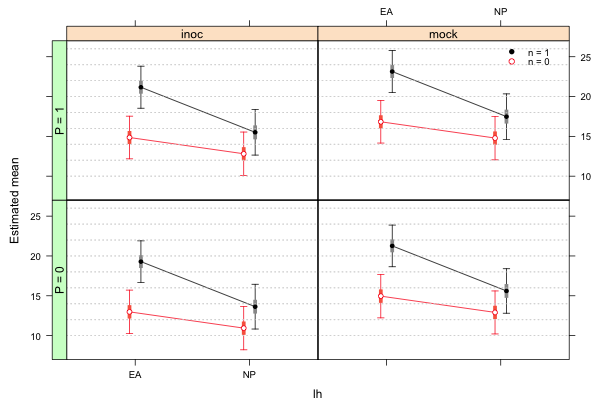 |
| Fig. 3 Lattice graph modified by the useOuterStrips function of the latticeExtra package |
R Code
A compact collection of all the R code displayed in this document appears here.
Course Home Page