Assignment 4—Solution
poplars <- read.table(ecol 563/poplars.txt', header=T)
poplars[1:8,]
weight trt block P L N K
1 13.9 O 1 absent absent absent absent
2 14.3 O 2 absent absent absent absent
3 15.8 O 3 absent absent absent absent
4 14.2 P 1 present absent absent absent
5 22.8 P 2 present absent absent absent
6 22.1 P 3 present absent absent absent
7 14.7 PK 1 present absent absent present
8 12.8 PK 2 present absent absent present
Question 1
Method 1
Following the hint I use the strsplit function to split the elements of the trt variable into individual components. For the split argument I enter two quotes with nothing between them.
out.sp <- strsplit(as.character(poplars$trt), split="")
out.sp[1:8]
[[1]]
[1] "O"
[[2]]
[1] "O"
[[3]]
[1] "O"
[[4]]
[1] "P"
[[5]]
[1] "P"
[[6]]
[1] "P"
[[7]]
[1] "P" "K"
[[8]]
[1] "P" "K"
The object that strsplit creates is called a list. Lists are a generalization of data frames in which the individual components can have different lengths as well as be different kinds of objects. To access an individual element of a list we need to use the double bracket notation.
out.sp[[8]]
[1] "P" "K"
out.sp[[8]][2]
[1] "K"
If we use the intersection operator, %in%, to determine if the character 'L' is in the list we get an uninformative answer.
'L' %in% out.sp
[1] TRUE
It just tells us that 'L' was found somewhere in the list, not where it was found. To determine the locations of 'L' we need to operate on each element of the list separately. The sapply function will do that for us. If we make the list, out.sp, the first argument of sapply then the function we specify in the second argument will be applied to each element of out.sp separately. The function we need is the following: function(x) 'L' %in% x. Each time a different element of the list is inserted as the variable x.
sapply(out.sp, function(x) 'L' %in% x)
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[15] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
[29] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[43] TRUE TRUE TRUE TRUE TRUE TRUE
A second way of obtaining the same result is to make the 1:48 the first argument of sapply (where 48 is the number of elements in the list). Then the function becomes: function(x) 'L' %in% out.sp[[x]]. This time the numbers 1 through 48 will be inserted sequentially for x and the corresponding element of the list will be tested to see if 'L' is an element.
sapply(1:48, function(x) 'L' %in% out.sp[[x]])
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[15] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
[29] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[43] TRUE TRUE TRUE TRUE TRUE TRUE
With this output we can use the ifelse function to conditionally assign the values 'present' or 'absent' to a new variable as follows.
ifelse(sapply(out.sp, function(x) 'L' %in% x), 'present', 'absent')
[1] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[9] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[17] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[25] "present" "present" "present" "present" "present" "present" "present" "present"
[33] "present" "present" "present" "present" "present" "present" "present" "present"
[41] "present" "present" "present" "present" "present" "present" "present" "present"
We repeat this for the three remaining factors assigning the results to a variable.
poplars$L <- ifelse(sapply(out.sp, function(x) 'L' %in% x), 'present', 'absent')
poplars$N <- ifelse(sapply(out.sp, function(x) 'N' %in% x), 'present', 'absent')
poplars$P <- ifelse(sapply(out.sp, function(x) 'P' %in% x), 'present', 'absent')
poplars$K <- ifelse(sapply(out.sp, function(x) 'K' %in% x), 'present', 'absent')
Method 2
R has a number of search and replace functions. One of these is grep. The grep function takes a string to search for as its first argument and the object to search as the second argument. If the second argument is a vector grep gives us the index numbers of the entries in the vector where the string was found.
grep('L',poplars$trt)
[1] 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
We can use this as follows. First we create a new character variable all of whose values are 'absent'.
poplars$L <- 'absent'
poplars$L
[1] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[10] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[19] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[28] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[37] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[46] "absent" "absent" "absent"
Next we change the entries whose indices were returned by grep to 'present'.
poplars$L[grep('L',poplars$trt)] <- 'present'
poplars$L
[1] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[9] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[17] "absent" "absent" "absent" "absent" "absent" "absent" "absent" "absent"
[25] "present" "present" "present" "present" "present" "present" "present" "present"
[33] "present" "present" "present" "present" "present" "present" "present" "present"
[41] "present" "present" "present" "present" "present" "present" "present" "present"
Finally we convert the result to a factor.
poplars$L <- factor(poplars$L)
To create the other factor variables we repeat these three steps for 'N', 'P', and 'K'.
Question 2
Checking for block × treatment interaction
The design is a randomized block design with no replication of treatment within block. Although we can't formally test for a block × treatment interaction we can examine the patterns graphically. I use the interaction.plot function to plot the treatment means separately by block to see if there are any obvious patterns.
interaction.plot(poplars$trt, poplars$block, poplars$weight, axes=F)
axis(1,at=1:16, labels=levels(poplars$trt), cex.axis=.7)
axis(2)
box()
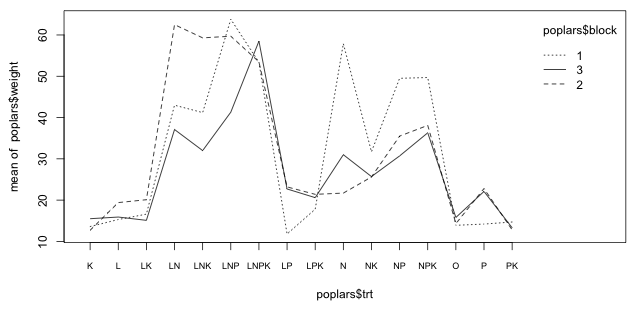
Fig. 1 Interaction plot of the block × treatment effects
With 16 treatments perfect parallelism of the profiles is difficult to achieve. Fig. 1 shows some crisscrossing of the profiles indicating the effects are not the same across blocks. There are clearly some issues here but with only three blocks it's difficult to determine how serious to take this. Some of the crisscrossing is just random noise and/or involve treatments or effects that are not significant. The one positive thing one can assert is that the basic pattern of treatment effects (which ones have large effects and which ones have small effects on the response) appears to be more or less consistent in the three blocks.
With only three blocks we don't have much power to carry out a formal test for specific kinds of interaction. We can carry out the Tukey test for non-additivity as follows.
out0 <- lm(weight ~ factor(block)+trt, data=poplars)
coef(out0)
(Intercept) factor(block)2 factor(block)3 trtL trtLK
15.6000000 -0.3437500 -4.6562500 2.9333333 3.3333333
trtLN trtLNK trtLNP trtLNPK trtLP
33.6000000 30.2333333 41.0000000 41.2000000 5.3000000
trtLPK trtN trtNK trtNP trtNPK
6.0000000 22.9333333 13.7333333 24.6333333 27.4333333
trtO trtP trtPK
0.7333333 5.7666667 -0.3333333
blockcoefs <- c(1,coef(out0)[2:3])
treatcoefs <- c(1, coef(out0)[4:18])
ab <- rep(blockcoefs,16)*rep(treatcoefs,each=3)
# Tukey test
out0a <- update(out0,.~.+ab)
anova(out0a)
Analysis of Variance Table
Response: weight
Df Sum Sq Mean Sq F value Pr(>F)
factor(block) 2 215.4 107.72 1.5932 0.2205
trt 15 10310.1 687.34 10.1658 8.07e-08 ***
ab 1 61.9 61.89 0.9154 0.3466
Residuals 29 1960.8 67.61
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
So, the product term is not significant. We can reject the presence of a multiplicative interaction between block and treatment effects.
Fitting the randomized block design model
I start by fitting the fixed effects version of the randomized block design including the four-factor interaction of the factors L, N, P, and K.
out1 <- lm(weight~factor(block)+L*P*N*K, data=poplars)
anova(out1)
Analysis of Variance Table
Response: weight
Df Sum Sq Mean Sq F value Pr(>F)
factor(block) 2 215.4 107.7 1.5978 0.219094
L 1 884.9 884.9 13.1254 0.001064 **
P 1 354.8 354.8 5.2623 0.028968 *
N 1 8350.3 8350.3 123.8513 3.58e-12 ***
K 1 43.9 43.9 0.6510 0.426106
L:P 1 2.0 2.0 0.0303 0.863014
L:N 1 395.0 395.0 5.8590 0.021761 *
P:N 1 108.3 108.3 1.6063 0.214763
L:K 1 23.4 23.4 0.3468 0.560354
P:K 1 20.7 20.7 0.3066 0.583876
N:K 1 2.8 2.8 0.0409 0.841163
L:P:N 1 1.3 1.3 0.0193 0.890482
L:P:K 1 1.4 1.4 0.0213 0.884976
L:N:K 1 4.1 4.1 0.0614 0.805936
P:N:K 1 79.8 79.8 1.1840 0.285216
L:P:N:K 1 37.3 37.3 0.5529 0.462924
Residuals 30 2022.7 67.4
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
For comparison I fit a model using the nlme package in which blocks are treated as random.
library(nlme)
lme.model <- lme(weight~L*P*N*K, random=~1|block, data=poplars)
anova(lme.model)
numDF denDF F-value p-value
(Intercept) 1 30 403.4235 <.0001
L 1 30 13.1254 0.0011
P 1 30 5.2623 0.0290
N 1 30 123.8513 <.0001
K 1 30 0.6510 0.4261
L:P 1 30 0.0303 0.8630
L:N 1 30 5.8590 0.0218
P:N 1 30 1.6063 0.2148
L:K 1 30 0.3468 0.5604
P:K 1 30 0.3066 0.5839
N:K 1 30 0.0409 0.8412
L:P:N 1 30 0.0193 0.8905
L:P:K 1 30 0.0213 0.8850
L:N:K 1 30 0.0614 0.8059
P:N:K 1 30 1.1840 0.2852
L:P:N:K 1 30 0.5529 0.4629
The results are identical. Based on the ANOVA table we can drop the four-factor and all the three-factor interactions. It appears that the only significant two-factor interaction is the L:N interaction. (Note: The reported test of blocks in the lm output is not appropriate. The error term in the model is the block × treatment interaction and isn't an appropriate measure of background variability for testing the block effect. In any case, we should retain the block term in the model because it is part of the experimental design.)
Because the data are balanced the order we fit the terms doesn't matter, so I drop all the non-significant 2-factor interactions too.
lme.model1 <- lme(weight~L*N+P+K, random=~1|block, data=poplars)
anova(lme.model1)
numDF denDF F-value p-value
(Intercept) 1 40 403.4236 <.0001
L 1 40 15.3649 0.0003
N 1 40 144.9839 <.0001
P 1 40 6.1602 0.0174
K 1 40 0.7621 0.3879
L:N 1 40 6.8587 0.0124
The main effect of K is not significant so I drop it leaving the following model.
lme.model2 <- lme(weight~L*N+P, random=~1|block, data=poplars)
anova(lme.model2)
numDF denDF F-value p-value
(Intercept) 1 41 403.4236 <.0001
L 1 41 15.4546 0.0003
N 1 41 145.8301 <.0001
P 1 41 6.1962 0.0170
L:N 1 41 6.8988 0.0121
Question 3
I examine the summary table of the final model.
summary(lme.model2)
Linear mixed-effects model fit by REML
Data: poplars
AIC BIC logLik
323.7645 336.0929 -154.8823
Random effects:
Formula: ~1 | block
(Intercept) Residual
StdDev: 1.775939 7.567076
Fixed effects: weight ~ L * N + P
Value Std.Error DF t-value p-value
(Intercept) 12.75625 2.648767 41 4.815919 0.0000
Lpresent 2.85000 3.089246 41 0.922555 0.3616
Npresent 20.64167 3.089246 41 6.681782 0.0000
Ppresent 5.43750 2.184427 41 2.489212 0.0170
Lpresent:Npresent 11.47500 4.368853 41 2.626547 0.0121
In the final model there is a significant main effect due to P and a significant interaction between L and N. The effect of each nutrient is to increase new growth. P increases growth by 5.4 g. L alone increases growth by 2.8 g, N alone increases growth by 20.6 g. The combination of L and N together increase growth by an additional 11.5 g over what each of these soil additives contributes alone.
Question 4
Because there is a significant two-factor interaction between L and N, the graph we construct should focus on explicating the nature of that interaction. Because there is only a main effect of P, the effect of P will only be to shift the two-factor interaction vertically. Thus it makes sense to display the results of the experiment as a panel graph in which each panel shows a different level of P while the panel itself displays the interaction between L and N.
I begin by constructing a data frame that contains the four different ways of combining the levels of L and N.
g <- expand.grid(L=levels(poplars$L), N=levels(poplars$N))
g
L N
1 absent absent
2 present absent
3 absent present
4 present present
I next write a function to generate the regressors of the regression model.
fixef(lme.model2)
(Intercept) Lpresent Npresent Ppresent
12.75625 2.85000 20.64167 5.43750
Lpresent:Npresent
11.47500
# write a function to return values of the regressors for choices of L, N, and P
cvec <- function(L,N,P) c(1, L=='present', N=='present', P=='present', (L=='present')*(N=='present'))
I next write a second function that applies the cvec function to the matrix g that contains the various ways of combining the levels of L and N for a specific value of P to produce a matrix of the values of the model regressors. I generate two matrices: one for the case when P is absent and the other for when P is present.
# make function to obtain regressors for all combinations of L and N for a specific P
cmat <- function(P) t(apply(g, 1, function(x) cvec(x[1], x[2], P)))
# construct regressors when P = 'absent'
cmat1 <- cmat('absent')
# construct regressors when P = 'present'
cmat2 <- cmat('present')
cmat1
L N L
[1,] 1 0 0 0 0
[2,] 1 1 0 0 0
[3,] 1 0 1 0 0
[4,] 1 1 1 0 1
cmat2
L N L
[1,] 1 0 0 1 0
[2,] 1 1 0 1 0
[3,] 1 0 1 1 0
[4,] 1 1 1 1 1
To calculate difference-adjusted confidence intervals we need the function from lecture 8.
ci.func2 <- function(rowvals, glm.vmat) {
nor.func1a <- function(alpha, sig) 1-pnorm(-qnorm(1-alpha/2) * sum(sqrt(diag(sig))) / sqrt(c(1,-1) %*% sig %*%c (1,-1))) - pnorm(qnorm(1-alpha/2) * sum(sqrt(diag(sig))) / sqrt(c(1,-1) %*% sig %*% c(1,-1)), lower.tail=F)
nor.func2 <- function(a,sigma) nor.func1a(a,sigma)-.95
n <- length(rowvals)
xvec1b <- numeric(n*(n-1)/2)
vmat <- glm.vmat[rowvals,rowvals]
ind <- 1
for(i in 1:(n-1)) {
for(j in (i+1):n){
sig <- vmat[c(i,j), c(i,j)]
#solve for alpha
xvec1b[ind] <- uniroot(function(x) nor.func2(x, sig), c(.001,.999))$root
ind <- ind+1
}}
1-xvec1b
}
Technically this function is only appropriate for large samples. For small samples the normal approximation is suspect and we should probably use a t-distribution. Recall though that there is an issue with how to correctly calculate degrees of freedom in mixed effects models. The lme function does return the degrees of freedom it uses for its tests. They're contained in the $fixDF$X component of the model.
# degrees of freedom are located in the $fixDF$X component
lme.model2$fixDF$X
(Intercept) Lpresent Npresent Ppresent
41 41 41 41
Lpresent:Npresent
41
If we compare the normal quantile to the quantile of a t-distribution with 41 degrees of freedom we see that there is a noticeable difference.
# choosing t or normal makes a small difference here
qnorm(.025)
[1] -1.959964
qt(.025,41)
[1] -2.019541
To use these we'd have to replace the qnorm and pnorm functions in ci.func2 with qt and pt and add an argument that specifies the degrees of freedom. The effect that using the normal distribution rather than the t-distribution will have on the confidence intervals is that our intervals based on the normal distribution will be about 0.15 units too short.
I obtain the variance-covariance matrices of the means separately for the two different values of P.
vmat1 <- cmat1 %*% vcov(lme.model2) %*% t(cmat1)
vmat2 <- cmat2 %*% vcov(lme.model2) %*% t(cmat2)
I run the ci.func2 function and find that a 75% confidence interval should be used for the difference-adjusted confidence levels.
# obtain difference-adjusted confidence intervals
ci.func2(1:4,vmat1)
[1] 0.746944 0.746944 0.746944 0.746944 0.746944 0.746944
ci.func2(1:4,vmat2)
[1] 0.746944 0.746944 0.746944 0.746944 0.746944 0.746944
I modify the make.data function from lecture 8 to generate a data frame of means, standard errors, and confidence intervals. The changes are highlighted.
# rewrite the make.data function from lecture 9 to work here
make.data <- function(P,model) {
#variance-covariance matrix of the means
vmat <- cmat(P) %*% vcov(model) %*% t(cmat(P))
# difference-adjusted confidence levels
vals1 <- ci.func2(1:4, as.matrix(vmat))
# levels of lh and n, means, and standard errors
part1 <- data.frame(g,
est=as.vector(cmat(P)%*%fixef(model)), se=sqrt(diag(vmat)))
# 95% intervals
part1$low95 <- part1$est + qnorm(.025)*part1$se
part1$up95 <- part1$est + qnorm(.975)*part1$se
# difference-adjusted intervals
part1$low85 <- part1$est + qnorm((1-min(vals1))/2)*part1$se
part1$up85 <- part1$est + qnorm(1-(1-min(vals1))/2)*part1$se
# add value of P
part1$P <- P
# return value of function
part1
}
I generate the results separately for the two values of P and combine the results into a single data frame.
# generate data for the graph
part0a <- make.data('absent',lme.model2)
part0b <- make.data('present',lme.model2)
# combine into a single data frame
fac.vals <- rbind(part0a,part0b)
fac.vals
L N est se low95 up95 low85 up85 P
1 absent absent 12.75625 2.648767 7.564761 17.94774 9.72882 15.78368 absent
2 present absent 15.60625 2.648767 10.414761 20.79774 12.57882 18.63368 absent
3 absent present 33.39792 2.648767 28.206428 38.58941 30.37049 36.42535 absent
4 present present 47.72292 2.648767 42.531428 52.91441 44.69549 50.75035 absent
5 absent absent 18.19375 2.648767 13.002261 23.38524 15.16632 21.22118 present
6 present absent 21.04375 2.648767 15.852261 26.23524 18.01632 24.07118 present
7 absent present 38.83542 2.648767 33.643928 44.02691 35.80799 41.86285 present
8 present present 53.16042 2.648767 47.968928 58.35191 50.13299 56.18785 present
The only change we need to make to the groups panel function is in the panel function that produces the grid lines.
# group panel function
my.panel <- function(x, y, subscripts, col, pch, group.number, ...) {
#subset variables for the current panel
low95 <- fac.vals$low95[subscripts]
up95 <- fac.vals$up95[subscripts]
low85 <- fac.vals$low85[subscripts]
up85 <- fac.vals$up85[subscripts]
myjitter <- c(-.05,.05)
col2 <- c('tomato','grey60')
#95% confidence interval
panel.arrows(x+myjitter[group.number], low95, x+myjitter[group.number], up95, angle=90,
code=3, length=.05, col=col)
#difference-adjusted confidence interval
panel.segments(x+myjitter[group.number], low85, x+myjitter[group.number], up85,
col=col2[group.number], lineend=1, lwd=5)
# connect means with line segments
panel.lines(x+myjitter[group.number], y, col=col)
# add point estimates for the means
panel.xyplot(x+myjitter[group.number], y, col='white', pch=16)
panel.xyplot(x+myjitter[group.number], y, col=col, pch=pch, ...)
# grid lines
panel.abline(h=seq(0,70,2), col='lightgrey', lty=3)
}
The prepanel function needs no changes.
# prepanel function to set limits for panels
prepanel.ci2 <- function(x, y, ly, uy, subscripts, ...){
list(ylim=range(y, uy[subscripts], ly[subscripts], finite=T))}
The changes I made to the xyplot call are highlighted.
library(lattice)
xyplot(est~L|factor(P, level=c('absent','present'), labels=paste('P = ', c('absent','present'), sep='')), xlab ='L', ylab='Estimated mean', groups=N, data=fac.vals, col=c(2,1), pch=c(1,16), prepanel=prepanel.ci2, ly=fac.vals$low95, uy=fac.vals$up95, layout=c(2,1), panel.groups=my.panel, panel="panel.superpose", key=list(x=.05, y=.82, corner=c(0,0), points=list(pch=c(16,1), col=1:2, cex=.9), text=list(c('N = 1','N = 0'), cex=.8)))
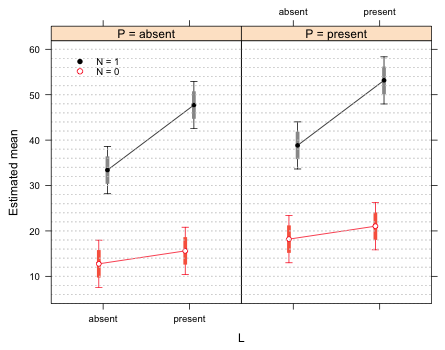
Fig. 2 Interaction plot with 75% difference-adjusted confidence intervals
To verify that the graph is correct we can compare the inferences we would draw from the graph to what is shown to the summary table of the model.
summary(lme.model2)
Linear mixed-effects model fit by REML
Data: poplars
AIC BIC logLik
323.7645 336.0929 -154.8823
Random effects:
Formula: ~1 | block
(Intercept) Residual
StdDev: 1.775939 7.567076
Fixed effects: weight ~ L * N + P
Value Std.Error DF t-value p-value
(Intercept) 12.75625 2.648767 41 4.815919 0.0000
Lpresent 2.85000 3.089246 41 0.922555 0.3616
Npresent 20.64167 3.089246 41 6.681782 0.0000
Ppresent 5.43750 2.184427 41 2.489212 0.0170
Lpresent:Npresent 11.47500 4.368853 41 2.626547 0.0121
- The L effect (when N = 0) is not significant (p = 0.36). This correctly corresponds to the overlapping 75% confidence intervals of the N = 0 profile.
- The N effect (when L = 0) is significant (p < .0001) and this corresponds to the non-overlapping 75% confidence intervals of the two N profiles when L = 0.
- The L:N interaction is significant (p = 0.01). This is not directly visible from the graph but if we were to translate the N = 0 profile so that it overlaps the N = 1 profiles, the two 75% confidence intervals for L = 1 would fail to overlap.
- The P effect is significant (p = 0.01). When we examine the graph we see that the corresponding 75% difference-adjusted interval pairs in the two P panels overlap. Thus the choice of a 75% interval does not allow us to draw correct conclusions when we compare observations across panels.
If we wish to present a panel graph in which the reader is allowed to make all pairwise comparisons then we'll need to find the appropriate confidence levels using all eight means. I recreate the g matrix of unique predictor combinations, the corresponding matrix of regressor values cmat, and calculate the difference-adjusted confidence levels.
g <- expand.grid(L=levels(poplars$L), N=levels(poplars$N), P=levels(poplars$P))
g
L N P
1 absent absent absent
2 present absent absent
3 absent present absent
4 present present absent
5 absent absent present
6 present absent present
7 absent present present
8 present present present
# obtain values of the regressors for each of the 8 means
cmat <- t(apply(g, 1, function(x) cvec(x[1], x[2], x[3])))
cmat
L N P L
[1,] 1 0 0 0 0
[2,] 1 1 0 0 0
[3,] 1 0 1 0 0
[4,] 1 1 1 0 1
[5,] 1 0 0 1 0
[6,] 1 1 0 1 0
[7,] 1 0 1 1 0
[8,] 1 1 1 1 1
# obtain the variance-covariance matrix of the means
vmat <- cmat %*% vcov(lme.model2) %*% t(cmat)
# obtain difference-adjusted confidence levels
# we see they fall into three categories: .58, .75, .84
ci.func2(1:8, vmat)
[1] 0.7469440 0.7469440 0.7469440 0.5810168 0.8384114 0.8384114 0.8384114 0.7469440
[9] 0.7469440 0.8384114 0.5810168 0.8384114 0.8384114 0.7469440 0.8384114 0.8384114
[17] 0.5810168 0.8384114 0.8384114 0.8384114 0.8384114 0.5810168 0.7469440 0.7469440
[25] 0.7469440 0.7469440 0.7469440 0.7469440
Three different confidence levels are shown. The 0.75 level should be used to compare means in the same panel. The 0.58 level should be used to compare means in different panels (different values of P) that have the same values of L and N. The 0.84 level should be used to compare means in different panels (different values of P) in which one or both of the levels of L and N are different.
Because the graph we're constructing is just a tool for summarizing the model it may not be necessary to use all three confidence levels. I redo the interaction plot using 84% confidence levels to see if they're needed or whether the 75% intervals would suffice. I redo the the make.data function for this purpose.
make.data4 <- function(vals1,model) {
#variance-covariance matrix of the means
vmat <- cmat %*% vcov(model) %*% t(cmat)
# levels of lh and n, means, and standard errors
part1 <- data.frame(g,
est=as.vector(cmat%*%fixef(model)), se=sqrt(diag(vmat)))
# 95% intervals
part1$low95 <- part1$est + qnorm(.025)*part1$se
part1$up95 <- part1$est + qnorm(.975)*part1$se
# difference-adjusted intervals
part1$low85 <- part1$est + qnorm((1-min(vals1))/2)*part1$se
part1$up85 <- part1$est + qnorm(1-(1-min(vals1))/2)*part1$se
# return value of function
part1
}
# redo using .84 for the difference-adjusted confidence intervals
fac.vals <- make.data4(.84,lme.model2)
fac.vals
L N P est se low95 up95 low85 up85
1 absent absent absent 12.75625 2.648767 7.564761 17.94774 9.034542 16.47796
2 present absent absent 15.60625 2.648767 10.414761 20.79774 11.884542 19.32796
3 absent present absent 33.39792 2.648767 28.206428 38.58941 29.676209 37.11962
4 present present absent 47.72292 2.648767 42.531428 52.91441 44.001209 51.44462
5 absent absent present 18.19375 2.648767 13.002261 23.38524 14.472042 21.91546
6 present absent present 21.04375 2.648767 15.852261 26.23524 17.322042 24.76546
7 absent present present 38.83542 2.648767 33.643928 44.02691 35.113709 42.55712
8 present present present 53.16042 2.648767 47.968928 58.35191 49.438709 56.88212
xyplot(est~L|factor(P, level=c('absent','present'),
labels=paste('P = ', c('absent', 'present'), sep='')),
xlab ='L', ylab='Estimated mean', groups=N, data=fac.vals,
col=c(2,1), pch=c(1,16), prepanel=prepanel.ci2, ly=fac.vals$low95,
uy=fac.vals$up95, layout=c(2,1), panel.groups=my.panel, panel="panel.superpose",
key=list(x=.05, y=.82, corner=c(0,0), points=list(pch=c(16,1), col=1:2, cex=.9),
text=list(c('N = 1','N = 0'), cex=.8)))
Fig. 3 Interaction plot with 84% difference-adjusted confidence intervals
If we make the cross-panel comparisons permitted by these intervals we see that all the pairwise comparisons are significant. This is the same conclusion we would have drawn by using the shorter 75% intervals, therefore we don't need to show both. The 75% intervals are sufficient for drawing the correct inferences.
Finally I examine the 58% intervals. This time I add them to Fig. 2 so that the 95% , 75%, and 58% intervals are all shown. I redo the make.data function so that all three intervals are created. I also modify the group panels function to add these new intervals for each group.
# rewrite make.data function so that it returns two difference-adjusted intervals
make.data5 <- function(vals1, vals2, model) {
#variance-covariance matrix of the means
vmat <- cmat %*% vcov(model) %*% t(cmat)
# levels of lh and n, means, and standard errors
part1 <- data.frame(g,
est = as.vector(cmat%*%fixef(model)), se=sqrt(diag(vmat)))
# 95% intervals
part1$low95 <- part1$est + qnorm(.025)*part1$se
part1$up95 <- part1$est + qnorm(.975)*part1$se
# difference-adjusted intervals
part1$low85 <- part1$est + qnorm((1-min(vals1))/2)*part1$se
part1$up85 <- part1$est + qnorm(1-(1-min(vals1))/2)*part1$se
part1$low58 <- part1$est + qnorm((1-min(vals2))/2)*part1$se
part1$up58 <- part1$est + qnorm(1-(1-min(vals2))/2)*part1$se
# return value of function
part1
}
# obtain data
fac.vals <- make.data5(.75,.58,lme.model2)
# rewrite group panels function so that it draws two difference-adjusted intervals
my.panel2 <- function(x, y, subscripts, col, pch, group.number, ...) {
#subset variables for the current panel
low95 <- fac.vals$low95[subscripts]
up95 <- fac.vals$up95[subscripts]
low85 <- fac.vals$low85[subscripts]
up85 <- fac.vals$up85[subscripts]
low58 <- fac.vals$low58[subscripts]
up58 <- fac.vals$up58[subscripts]
myjitter <- c(-.05,.05)
col2 <- c('tomato','grey60')
#95% confidence interval
panel.arrows(x+myjitter[group.number], low95, x+myjitter[group.number], up95, angle=90, code=3, length=.05, col=col)
#difference-adjusted confidence interval
panel.segments(x+myjitter[group.number], low85, x+myjitter[group.number], up85, col=col2[group.number], lineend=1, lwd=5)
panel.segments(x+myjitter[group.number], low58, x+myjitter[group.number], up58, col='dodgerblue1', lineend=1, lwd=8)
# connect means with line segments
panel.lines(x+myjitter[group.number], y, col=col)
# add point estimates for the means
panel.xyplot(x+myjitter[group.number], y, col='white', pch=16)
panel.xyplot(x+myjitter[group.number], y, col=col, pch=pch, ...)
# grid lines
panel.abline(h=seq(0,70,2), col='lightgrey', lty=3)
}
# generate graph
xyplot(est~L|factor(P, level=c('absent','present'),
labels=paste('P = ', c('absent','present'), sep='')),
xlab ='L', ylab='Estimated mean', groups=N, data=fac.vals,
col=c(2,1), pch=c(1,16), prepanel=prepanel.ci2, ly=fac.vals$low95,
uy=fac.vals$up95, layout=c(2,1), panel.groups=my.panel2, panel="panel.superpose",
key=list(x=.05, y=.82, corner=c(0,0), points=list(pch=c(16,1), col=1:2, cex=.9),
text=list(c('N = 1','N = 0'), cex=.8)))
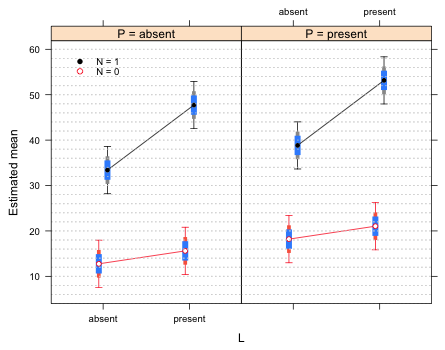
Fig. 4 Interaction plot with 58% and 75% difference-adjusted confidence intervals
The 58% intervals of means with the same values of L and N but different values of P do not overlap, which is correct. If we were to use the 58% intervals, rather than the 75% intervals, to make comparisons within the same panel we see that we would draw the same conclusions as we do with the 75% intervals. Therefore we don't need both of them. I redraw the graph using only 58% difference-adjusted confidence intervals.
fac.vals <- make.data4(.58,lme.model2)
xyplot(est~L|factor(P, level=c('absent','present'),
+ labels=paste('P = ', c('absent','present'), sep='')),
+ xlab ='L', ylab='Estimated mean', groups=N, data=fac.vals,
+ col=c(2,1), pch=c(1,16), prepanel=prepanel.ci2, ly=fac.vals$low95,
+ uy=fac.vals$up95, layout=c(2,1), panel.groups=my.panel, panel="panel.superpose",
+ key=list(x=.05, y=.82, corner=c(0,0), points=list(pch=c(16,1), col=1:2, cex=.9),
+ text=list(c('N = 1','N = 0'), cex=.8)))
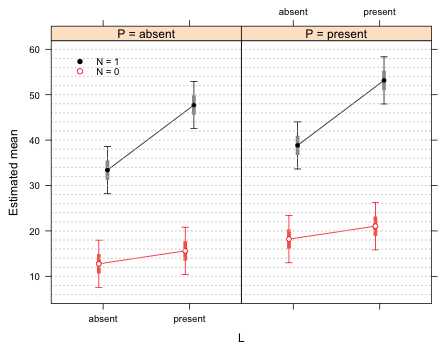
Fig. 5 Interaction plot with 58% difference-adjusted confidence intervals
Course Home Page