So far in this course we've focused exclusively on what is called a model-based approach to statistics. In statistics a model is a proposal for how we think our data could have been generated. A statistical model contains both a systematic and a random component each of which has to specified by us. Model-based approaches while intuitively appealing have some obvious problems associated with them.
There is another approach to statistical modeling in which the actual model itself is secondary. Instead the algorithm used to obtain the model takes center stage. In a regression setting, this algorithm-based approach is generally some variation of what's called recursive binary partitioning (implemented in the rpart package of R). It is also called CART, an acronym for classification and regression trees, but this is also the name of a commercial product developed by one of the pioneers in this area, Leo Breiman (Breiman et al. 1984).
Binary recursive partitioning is typically lumped into a category of methods that are referred to as "machine learning" or "statistical learning" methods. Members of this group include support vector machines, neural networks, and many others. These methods have virtually nothing in common with each other except for the fact that they originated in the field of computer science rather than statistics. In some cases computer scientists reinvented methodologies that already had a long history in statistics. In doing so they managed to create their own terminology leaving us today with different descriptions of otherwise identical methods. As a result much of modern statistical learning theory is an awkward amalgamation of computer science and statistics. Good introductions to this area include Berk (2008) and Hastie et al. (2009). Introductory treatments for ecologists are Fielding (1999) and Olden et al. (2008).
In binary recursive partitioning the goal is to partition the predictor space into boxes and then assign a numerical value to each box based on the values of the response variable for the observations assigned to that box. At each step of the partitioning process we are required to choose a specific variable and a split point for that variable that we then use to divide all or a portion of the data set into two groups. This is done by selecting a group to divide and then examining all possible variables and all possible split points of those variables. Having selected the combination of group, variable, and split point that yields the greatest improvement in the fit criterion we are using, we then divide that group into two parts. This process then repeats.
For a continuous response the object that is created is called a regression tree, whereas if the response is a categorical variable it's called a classification tree. Classification and regression trees are collectively referred to as decision trees. The usual fit criterion for a regression tree is the residual sum of squares, RSS. The construction of a generic regression tree model would proceed as follows.
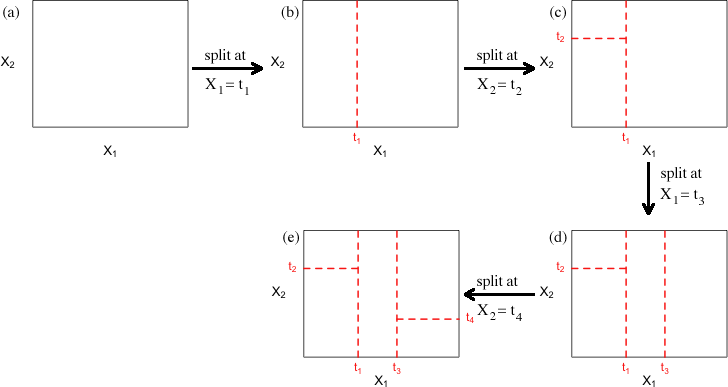
Fig. 1 illustrates a toy example of this process with only two variables X1 and X2. The rectangle shown in each panel is meant to delimit the range of the two variables. Here's a possible scenario for how the regression tree might evolve.
Fig. 1 Heuristic example of binary recursive partitioning with a predictor set consisting of two variables X1 and X2
This yields the five rectangular regions R1, R2, R3, R4, and R5 shown in Fig. 1e and Fig. 2a. Next we summarize the response variable by its mean, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , in each region. In an ordinary regression model with two variables, the regression model is visualized as a surface lying over the X1-X2 plane. For a model linear in X1 and X2, the surface is a plane. If the model contains a cross-product term X1X2, then the surface is curved. The model underlying a binary recursive partition can be visualized as a step surface such as the one shown in Fig. 2b. Over each of the regions shown in Fig. 2a we obtain a rectangular box whose cross-section is the given rectangular region and whose height is the mean of the response variable in that region.
, in each region. In an ordinary regression model with two variables, the regression model is visualized as a surface lying over the X1-X2 plane. For a model linear in X1 and X2, the surface is a plane. If the model contains a cross-product term X1X2, then the surface is curved. The model underlying a binary recursive partition can be visualized as a step surface such as the one shown in Fig. 2b. Over each of the regions shown in Fig. 2a we obtain a rectangular box whose cross-section is the given rectangular region and whose height is the mean of the response variable in that region.
(a) 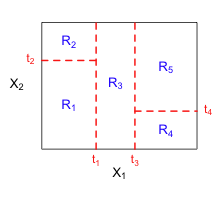 |
(b)  |
Fig. 2 (a) The rectangular regions in the X1-X2 plane that were defined by the binary recursive partition shown in Fig. 1. (b) The regression surface for the response that corresponds to this binary recursive partition. Each box in (b) lies on one of the rectangular regions in (a) and its height corresponds to the mean of the response variable over that region. |
|
The formula for the regression surface in Fig. 2b is the following.
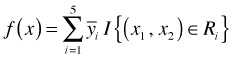
Here I is an indicator function that indicates whether the observation lies in the given rectangular region. Because an observation can only occur in one of the five regions, four of the terms in this sum are necessarily zero for each observation. As a result we just get ![]() for the region that contains the point.
for the region that contains the point.
Because at each stage of the recursive partition we are only allowed to divide previously split single regions, the algorithm itself can be visualized as a tree. Fig. 3a shows the tree that corresponds to the regions defined in Fig. 2a. The splitting rules used at the various steps of the algorithm are given at the branch points. By following the branches of the tree as dictated by splitting rules we arrive at the rectangular regions shown in Fig. 2a.
(a) 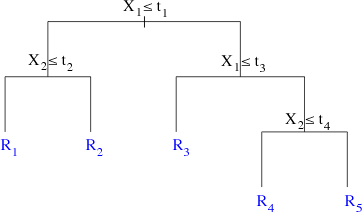 |
(b) 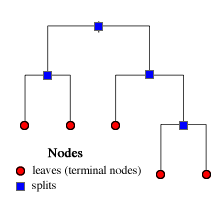 |
Fig. 3 (a) When we focus on the algorithm itself binary recursive partitioning yields a binary tree. (b) The terminology associated with regression and classification trees |
|
The branching points are called splits and branch endpoints are called leaves (or terminal nodes). Both the splits and the leaves are referred to as nodes (Fig 3b). In the heuristic tree of Fig. 3b there are four splits and five leaves for a total of nine nodes.
Step 1: Choose a variable and a split point.
For a continuous or ordinal variable with m distinct values, ξ1, ξ2, …, ξm, consider each value in turn. Each selection produces a partition consisting of two sets of values: ![]() and
and ![]() , i = 1, 2, … , m. Splits can only occur between consecutive data values. Thus there are m–1 possible partitions to consider. For a categorical (nominal) variable with m categories we have to consider all possible ways of assigning the categories to two groups. The splits can be anywhere and any category can be assigned to any group. Combinatorial arguments tell us that there are
, i = 1, 2, … , m. Splits can only occur between consecutive data values. Thus there are m–1 possible partitions to consider. For a categorical (nominal) variable with m categories we have to consider all possible ways of assigning the categories to two groups. The splits can be anywhere and any category can be assigned to any group. Combinatorial arguments tell us that there are ![]() ways in which this can be done. (With m categories there are 2m different subsets. Because the complement of each subset is another subset this corresponds to 2m–1 splits. One of the subsets includes everybody (or nobody) which is not a split so we reduce this number further by 1.)
ways in which this can be done. (With m categories there are 2m different subsets. Because the complement of each subset is another subset this corresponds to 2m–1 splits. One of the subsets includes everybody (or nobody) which is not a split so we reduce this number further by 1.)
Step 2: For each possible division calculate its impurity.
Different measures of impurity are used for continuous and categorical predictors.
Continuous response: For a continuous response y, suppose we select variable Xj and split point s that yield the following two groups.
![]() and
and ![]()
The usual measure of impurity used for continuous variables is the residual sum of squares. For the observations assigned to each group we calculate the mean of the response variable. The residuals sum of squares, RSS, for the current split is defined as follows.
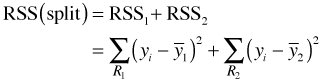
Before the data are split we calculate the overall residual sum of squares using the mean of all values of the response variable.
![]()
So for a continuous response we examine each variable Xj and all possible split points s and choose the one for which RSS0 – RSS(split) is the largest.
Categorical response: For categorical variables there are a number of different ways of calculating impurity. Let y be a categorical variable with m categories. Let
nik = number of observations of type k at node i
pik = proportion of observations of type k at node i
The following four measures of impurity are commonly used.
The impurity for a given partition is the sum of the impurities over all nodes, ![]() . For a categorical variable all four measures of impurity are minimized when all the observations at a node are of the same type. The goal in a classification tree is to choose splits that yield groups that are purer than in the current partition.
. For a categorical variable all four measures of impurity are minimized when all the observations at a node are of the same type. The goal in a classification tree is to choose splits that yield groups that are purer than in the current partition.
Step 3: Try to partition the current groups further. Having chosen a best partition at the current stage of the tree, we next try to partition each of the groups that were formed by considering all nodes in turn. We are only allowed to partition within existing partitions (not across partitions). It is adherence to this rule that produces the tree structure.
Step 4: At some point stop. The issue of stopping rules is discussed next time.
| Jack Weiss Phone: (919) 962-5930 E-Mail: jack_weiss@unc.edu Address: Curriculum for the Environment and Ecology, Box 3275, University of North Carolina, Chapel Hill, 27599 Copyright © 2012 Last Revised--April 10, 2012 URL: https://sakai.unc.edu/access/content/group/2842013b-58f5-4453-aa8d-3e01bacbfc3d/public/Ecol562_Spring2012/docs/lectures/lecture35.htm |