We'll spend the next three weeks discussing methods for handling correlated data. We focus on three distinct approaches.
This list leaves out a lot of other more specialized approaches, particularly those for dealing with specific sorts of spatial correlation. Examples include CAR (conditional autoregressive) and SAR (simultaneous autoregressive) models that are complicated instances of mixed effects models when observations have an identifiable neighborhood structure. These are both best handled from a Bayesian perspective.
If we are taking a likelihood perspective then the likelihood we've been formulating is wrong if the data are truly correlated. In the discrete case the likelihood of our data under a given model is the joint probability of obtaining our data under the given model.
![]()
Now if x1, x2, ... , xn are a random sample then the observations are independent and their joint probability can be written as a product of their identical marginal distributions.

Accordingly the log-likelihood is the sum of individual log probabilities. This is the scenario we've assumed in order to obtain the parameter estimates of generalized linear models.
If the data are not independent then the above factorization is invalid. As a result the likelihood and AIC are wrong, the results of model selection may be incorrect, and the parameter estimates and their standard errors may be affected. If we use least squares to estimate the model and we have normally distributed response, then the parameter estimates we obtain will still be correct but the reported significance tests for those parameters will be wrong. This reasons for this are the following.
It's worth noting that most ecological data sets possess spatial and/or temporal extent and thus will be correlated to some degree.
When we assume independence in formulating the likelihood, the independence is conditional on the values of the model parameters. In a regression model estimates of the parameters are functions of the model predictors. Consequently if the predictors in the model also vary both spatially and temporally, we expect that at least some if not all of the correlation in the response variable will be explained by the regression model. Given this our focus here will be the following. After fitting the best regression model we can, what should we do about any lingering correlation that remains in the response variable?
To introduce methods for dealing with correlated data we will focus on temporal data because temporal data are the easiest to model.
Because it generalizes ordinary least squares, generalized least squares (GLS) is largely restricted to situations in which a normal distribution makes sense as a probability model for the response. For non-normal correlated data the choices are murkier, so for the moment we'll focus exclusively on regression models with a normally distributed response. Generalized least squares requires us to formulate a specific model for the variances and covariances of our observations. This is not difficult with temporal data because there are some obvious choices. For this reason we will focus on analyzing temporal data using GLS.
In matrix notation, the ordinary regression problem can be written as follows.
![]()
Here
The method of least squares yields an explicit formula for the estimates of the components of β.
![]()
The least squares solution doesn't make any distributional assumptions but to obtain statistical tests and confidence intervals we need to assume a probability distribution for the response vector y. Least squares lends itself to assuming a normal distribution for y which we can write as follows.
![]()
Here I is the n × n identity matrix, a matrix of zeros except for ones on the diagonal. This is the matrix formulation of independence for a normally distributed response. We can also express this assumption in terms of the error vector of the regression equation.
![]()
This assumption coupled with the least squares solution leads to the theoretical distribution of the regression parameters β (normal distribution) and an explicit formula for their standard errors.
Generalized least squares (GLS) generalizes ordinary least squares to the case where the residuals have a normal distribution with an arbitrary covariance matrix Σ.
![]()
For convenience we will write the covariance matrix in the form ![]() . It turns out that not every matrix is a covariance matrix. Covariance matrices are rather special.
. It turns out that not every matrix is a covariance matrix. Covariance matrices are rather special.
![]()
for some nonsingular, symmetric matrix P. P act like the square root of V and is sometimes called a square root matrix.
It turns out that
![]()
so that we can uncorrelate the errors with an appropriate transformation, namely premultiplying the response vector by P–1. So, suppose we have the following generalized regression model.
![]()
We premultiply both sides of the regression equation by P–1 to obtain the following.
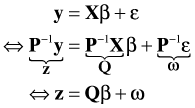
where now ![]() . This is just the ordinary least squares problem again with the variables and matrices relabeled. The formula for the solution was given above.
. This is just the ordinary least squares problem again with the variables and matrices relabeled. The formula for the solution was given above.
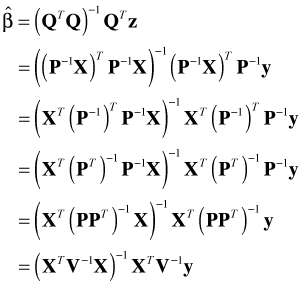
So as was the case with ordinary least squares we end up with an exact formula for the regression parameters, this time in terms of the design matrix and the unscaled covariance matrix V. Unfortunately the formula requires that we know V, so typically we'll need to estimate it first.
To make this problem feasible and to avoid overparameterization, the usual approach is to assume that V has a very simple form, a correlation structure that is based on a small number of parameters, and to jointly estimate the regression parameters and the covariance parameters. There are specific algorithms for special correlation structures, but a general approach is to use maximum likelihood estimation. This can be done by using the above solution for β (as well as the MLE expression for σ) and treating the log-likelihood as a function to be maximized over the unknown correlation parameters.
To implement generalized least squares we need to choose a parametric form for the matrix V. If we assume that the residuals all have the same variance, then the matrix V is the correlation matrix of the residuals. For temporal data the primary tool for identifying reasonable models for the correlation is the empirical autocorrelation function (ACF).
Suppose that a regression model has been fit to temporal data, consisting of either a single time series or a set of time series (repeated measures on different units), and that the standardized residuals have been extracted from the model.
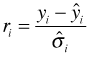
Here ![]() . We make the following what are called stationarity assumptions about the residuals.
. We make the following what are called stationarity assumptions about the residuals.
As a consequence of the stationarity assumptions, especially (2), we can define the residual autocorrelation at various lags by considering all the pairs of residuals that are the same number of time units apart (Fig. 1). Lag 1 observations are all pairs of observations that are one time unit apart, lag 2 observations are all pairs of observations that are two time units apart, etc.
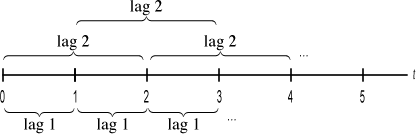
Fig. 1 Observations that are 1, 2, … time units apart
We assume that the residuals are sorted in time order. If the data consist of multiple time series that correspond to different observational units, then within each observational unit the residuals should be sorted in time order. For a single time series of length n we define the autocorrelation at lag ![]() as follows.
as follows.
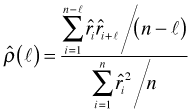
If we have M different time series of varying lengths then the average is taken over all the individual time series.
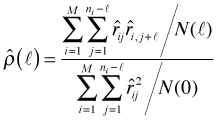
Here ![]() is the number of terms in the numerator sum (the total number of residual pairs a distance of
is the number of terms in the numerator sum (the total number of residual pairs a distance of ![]() time units apart) and N(0) is the total number of residuals. The autocorrelation function (ACF) is the lag
time units apart) and N(0) is the total number of residuals. The autocorrelation function (ACF) is the lag ![]() correlation,
correlation, ![]() , treated as a function of the lag
, treated as a function of the lag ![]() .
.
Observe that the formula for the lag ![]() autocorrelation is just a special case of the usual Pearson correlation formula except that here the means are zero and a different numbers of terms contribute to the numerator and denominator expressions.
autocorrelation is just a special case of the usual Pearson correlation formula except that here the means are zero and a different numbers of terms contribute to the numerator and denominator expressions.
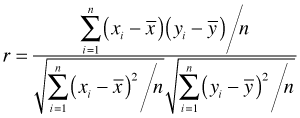
The autocorrelation function is usually examined graphically by plotting ![]() against
against ![]() in the form of a spike plot and then superimposing 95% (or Bonferroni-adjusted 95%) confidence bands. We expect with temporally ordered data that the correlation will decrease with increasing lag. Fig. 2 shows a plot of the ACF that is typically seen with temporally correlated data. Here the correlation decreases exponentially with lag.
in the form of a spike plot and then superimposing 95% (or Bonferroni-adjusted 95%) confidence bands. We expect with temporally ordered data that the correlation will decrease with increasing lag. Fig. 2 shows a plot of the ACF that is typically seen with temporally correlated data. Here the correlation decreases exponentially with lag.
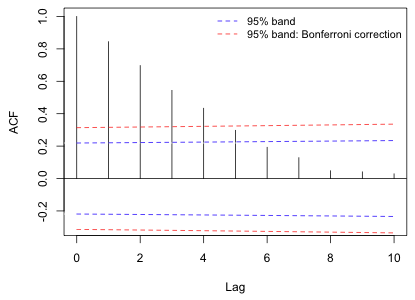
Fig. 2 Display of an ACF with 95% confidence bands
The confidence bands for the ACF are calculated using the following formula.
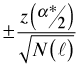
Here z(p) denotes the quantile of a standard normal distribution such that P(Z ≤ z(p)) = p. For an ordinary 95% confidence band we would set α* = .05. For a Bonferroni-corrected confidence bound in which we attempt to account for carrying out ten significance tests (corresponding to the ten nonzero lags shown in Fig. 2) we would use α* = .05/10.
| Jack Weiss Phone: (919) 962-5930 E-Mail: jack_weiss@unc.edu Address: Curriculum for the Environment and Ecology, Box 3275, University of North Carolina, Chapel Hill, 27599 Copyright © 2012 Last Revised--February 13, 2012 URL: https://sakai.unc.edu/access/content/group/2842013b-58f5-4453-aa8d-3e01bacbfc3d/public/Ecol562_Spring2012/docs/lectures/lecture15.htm |