In the classic case of simple linear regression we have one continuous variable called the response, usually denoted y, and a second continuous variable called the predictor, usually denoted x. The observations consist of the ordered pairs ![]() , i = 1, 2, … , n. A scatter plot of y versus x suggests there may be a systematic relationship between the two variables (Fig. 1a). In the simplest case we look for a straight-line relationship between them, an equation of the form
, i = 1, 2, … , n. A scatter plot of y versus x suggests there may be a systematic relationship between the two variables (Fig. 1a). In the simplest case we look for a straight-line relationship between them, an equation of the form
![]()
where β1 is the slope and β0 is the intercept, and ![]() denotes the corresponding point on the regression line (also called the predicted value).
denotes the corresponding point on the regression line (also called the predicted value).
The OLS solution to the linear regression problem is to find β0 and β1 that minimize the following quantity.
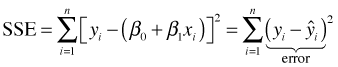
The quantity being squared is referred to as the regression error and corresponds to the vertical deviation of an observation from the regression line (Fig. 1b). The entire quantity that is minimized is called the sum of squared errors (SSE).
(a) 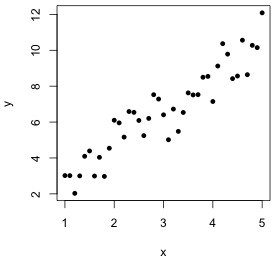 |
(b) 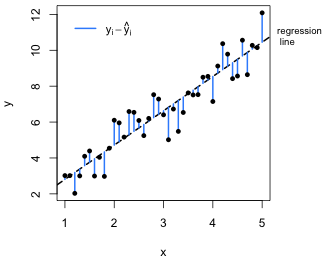 |
Fig. 1 (a) Scatter plot of y versus x suggesting a linear relationship. (b) The OLS regression line minimizes the sum of the squared vertical deviations from the regression line, 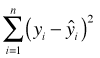 |
|
This problem is easily solved using calculus. To do so we obtain two derivatives, the derivative of SSE with respect to β0 and the derivative of SSE with respect to β1, set both derivatives equal to zero, and solve simultaneously for the parameters β0 and β1. We write the solution as follows.
![]()
where we place carets over the parameter symbols to indicate that these are the values that were estimated from the data using OLS.
Ordinary least squares is just one way of constructing a "best-fitting" line to a scatter plot of data. Other methods include the following.
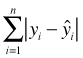 . This yields the L1-norm solution to the regression problem.
. This yields the L1-norm solution to the regression problem.The second and third methods listed above are sometimes referred to as Type II regressions, whereas OLS is referred to as Type I regression. Historically the OLS solution has been preferred because it was considered simpler to compute and has nice properties.
The regression problem of fitting a line to a 2-dimensional scatter plot of data can also be treated as a problem in n-dimensional geometry. The n observed values of the response variable define an n × 1 vector y and the corresponding n values of the predictor define an n × 1 vector x. The regression equation relates these two vectors in a matrix equation as follows.
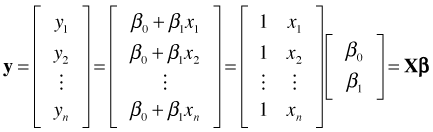
The matrix X is referred to as the design matrix of the system. Row-reducing the augmented matrix [X|y] to find a solution to this matrix equation is futile here. Linear algebra theory tells us that an n × 2 system of equations, where n > 2, typically corresponds to an inconsistent system of equations and will not have a solution. Of course we already knew this because we've seen that the points don't all lie on a single straight line (Fig. 1a).
The matrix product Xβ can be interpreted as taking a linear combination of the columns of the matrix X using coefficients that are the components of β.
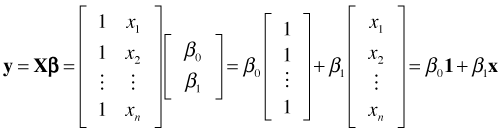
The vectors y, 1, and x in the above equation can be visualized as three vectors in n-dimensional space (Fig. 2). The vectors 1 and x define a plane in n-dimensional space (as do any two non-collinear vectors) and by specifying values for β0 and β1 in the above linear combination we obtain different points in that plane. As Fig. 2 shows, the vector y will typically not lie in the plane defined by the vectors 1 and x. For that reason the matrix equation fails to have a solution. The vector y cannot be written as a linear combination of the vectors 1 and x.
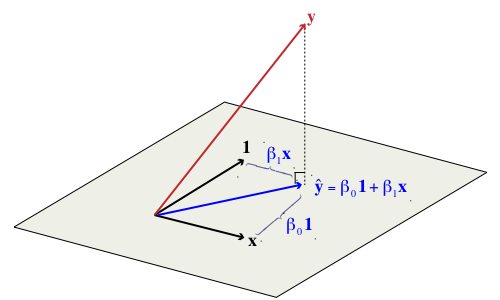
Fig. 2 The regression problem viewed as vector projection in n-dimensional space
We can salvage a solution to this problem as follows. Find the vector ![]() that lies in the plane defined by the vectors 1 and x such that its distance from the vector y is shortest. Geometrically we can obtain
that lies in the plane defined by the vectors 1 and x such that its distance from the vector y is shortest. Geometrically we can obtain ![]() by dropping a perpendicular from y onto the plane defined by 1 and x. Algebraically we do this by projecting the vector y onto this plane, a feat that is accomplished by premultiplying y by an appropriate projection matrix. The components of the coefficient vector β are obtained as follows.
by dropping a perpendicular from y onto the plane defined by 1 and x. Algebraically we do this by projecting the vector y onto this plane, a feat that is accomplished by premultiplying y by an appropriate projection matrix. The components of the coefficient vector β are obtained as follows.
![]()
and the projected vector ![]() is given by
is given by
![]()
where ![]() is the desired projection matrix.
is the desired projection matrix.
Interestingly this solution obtained using projection matrices is identical to the ordinary least squares (OLS) solution. So, we get the same answer to the regression problem regardless of whether we view it as a calculus minimization problem or a vector projection problem. Either way finding the coefficients of the regression equation is a straight-forward mathematical problem with a well-defined solution.
Everything we've done so far is just mathematics. So, where does statistics enter the picture? Mathematics gives us a line that best fits the data, where we define "best" in a way that suits us. If the data were obtained as a sample from a population then the equation fit to that specific data set is probably not that interesting by itself. It is the corresponding regression equation in the sampled population that we truly care about. The target population may be real (as when we have a list of potential observations and we've obtained only a subset of them) or more hypothetical (e.g., the set of all possible ways we might lay out a set of quadrats in a field and then count the number of individuals of a particular species in each quadrat).
What we want to be able to say is that the regression equation we obtained using our data set also represents the regression equation in the population. The concern we should have with estimating a regression equation based on a sample is that if we were to go back and collect data a second time the sample we would obtain would be different and produce a different regression equation. Because we know a sample-derived regression equation will vary from sample to sample we need to quantify how much it is likely to vary and include this information in our report.
Based on a single sample what can we say about the population that gave rise to it? Surprisingly, quite a lot. We don't actually have to go back and get additional samples.
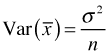
where σ2 can be estimated from s2, the variance of the sample data.
The OLS solution yields the best-fitting line to a data set, but to go further and draw inferences about the population from which the data were obtained we generally need to make additional assumptions about the sample and the population. The regression equation is then used to characterize a particular parameter in the distribution of the response variable y, often the mean of that distribution.
Multiple regression differs from simple linear regression in that we have multiple predictor variables. Mathematically multiple regression is just a trivial extension of the simple linear regression problem. The methods of solution that worked for simple linear regression also work for multiple regression. For example, if the multiple regression problem has three predictors x, z, and w so that the regression equation is
![]()
we can find the least squares solution by constructing the sum of squares error as before
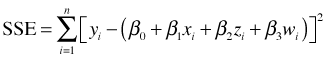
The only difference is that now instead of two partial derivatives there are four partial derivatives to calculate and set equal to zero. From a linear algebra perspective the difference between simple and multiple regression is even more trivial. In multiple regression the design matrix X just has more columns in it.

The solution is found in the same way as before, ![]() .
.
It's worth noting that the thing that makes linear regression "linear" is the fact that the regression equations can be written in terms of matrix multiplication. This means that fitting curves such as polynomials to a data set is still a linear regression problem even though the curve we obtain isn't a line. Suppose we wish to fit a parabola to a scatter plot of y versus x.
![]()
This is still a problem in linear regression because the regression equation can be expressed in matrix form as follows.
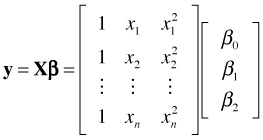
Having powers or functions of predictors in a regression equation poses no new problems. The equation is still linear. If the regression equation can be written as a matrix product of a data matrix times a vector of parameters, it's a linear equation.
Why is multiple regression generally preferable to simple linear regression?
We'll explore the concepts of confounding and interaction further in lecture 2.
| Jack Weiss Phone: (919) 962-5930 E-Mail: jack_weiss@unc.edu Address: Curriculum of the Environment and Ecology, Box 3275, University of North Carolina, Chapel Hill, 27599 Copyright © 2012 Last Revised--Jan 11, 2012 URL: https://sakai.unc.edu/access/content/group/2842013b-58f5-4453-aa8d-3e01bacbfc3d/public/Ecol562_Spring2012/docs/lectures/lecture1.htm |